Experiment Log: Comparing current findings with orignal paper
Date
2026-01-20
Hypothesis
The current architecture should produce the same results as the original paper.
Experimental Setup
- Model/Architecture: LeNet-1
- Dataset: MNIST
- Preprocessing: normalization, resizing (28x28)
- Hyperparameters:
- Learning rate: 0.01
- Batch size: 32
- Epochs: 20
- Loss Function: Cross Entropy Loss
- Others:
- Learning rate: 0.01
Procedure
- Using Pytorch to get the MNIST data.
- Setting:
- The input image size to 28x28.
- The
CrossEntropyLoss()as the Loss function. - The optimizer:
optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.9)
- Training on 20 epochs.
Results
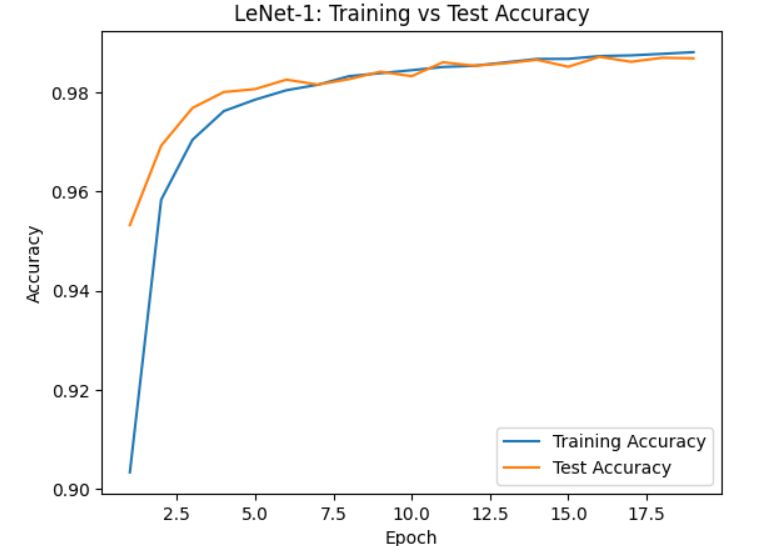
- Training Loss: 0.0397
- Training Accuracy Rate: 98.80%
- Test Accuracy: 0.9868
- Test Error Rate: 1.32%
- Other Metrics:
Visualizations

Observations
- I notice that I got a lower error rate for the test dataset, although the same architecture and procedures are used. However this is expected range for the network due to its small size.
Conclusions
- The results are expected.
Next Steps / Ideas
- Rerun the training using the max pooling insted of the average.
- Try with
ReLUinsted ofTanh. - Add padding.
Comments